
放一下操作系统第六章复习笔记吧
¶虚拟存储器的概念
-
局部性原理
-
虚拟存储器的概念
-
局部性的特征体现
-
理解虚拟存储器
-
虚拟存储器的容量
¶虚拟存储器的任务
-
逻辑上扩充内存容量
¶局部性原理
-
时间局部性:
一条指令被执行了,则在不久的将来它可能再被执行。
-
空间局部性:
若某一存储单元被使用,则在一定时间内,与该存储单元相邻的单元可能被使用。
只需要让程序当前需要运行的内容存在于内存中,程序就能跑
¶虚拟存储器的定义
具有请求调入功能[1]和置换功能,能从逻辑上对内存容量加以扩充的一种存储器系统。
虚拟存储器的容量 = $min($ 内存 $+$ 外存 $,$ cpu寻址空间 $)$
¶虚拟存储器的特征
-
多次性
-
对换性
-
虚拟性
¶虚拟存储器的实现
¶请求分页系统
-
硬件支持:页表、缺页中断、地址变换机构
-
软件支持:请求调页软件、页面置换软件
¶请求分段系统
-
硬件支持:段表、缺段中断、地址变换机构。
-
软件支持:请求调段软件、段置换软件。
¶段页式虚拟存储器
-
增加请求调页和页面置换。
¶请求分页存储管理

¶目标评价
¶硬件支持
¶页表机制
需要在进程页表[2]中添加若干项
-
状态位P:指示该页是否在内存
-
访问字段A:记录该页在一段时间内被访问的次数
-
修改位M:也称脏位,标志该页是否被修改过
-
外存地址:指示该页在外存中的地址(物理块号)
¶缺页中断机构
-
在指令执行期间产生和处理中断信号
-
一条指令在执行期间,可能产生多次缺页中断
关于 一条指令在执行期间,可能产生多次缺页中断
指令本身产生的缺页中断
-
指令取指
cpu在只从一条指令时,需要从主存取出指令。如果指令所在的虚拟页面尚未加载到主存,就会触发缺页中断。
操作数访问导致的缺页中断
-
直接操作数
如果指令是使用了内存中的数据作为操作数,操作数对应的页面可能尚未加载,触发缺页中断
-
间接访问
指令可能需要通过指针或索引来访问内存中的数据。如果这些地址指向的页面不在主存,也会触发缺页中断
指令操作多次访问内存
一些复杂的指令(尤其在CISC架构[3]中)可能在执行期间涉及多个内存访问,每次访问可能触发缺页中断。例如:
-
字符串处理指令
一条指令可能遍历一个数组或字符串,多次访问内存中的页面。 -
多维数组操作
在访问二维或三维数组时,可能涉及多个页面。
页表访问产生的缺页中断
-
多级页表
虚拟地址到物理地址的转换需要访问页表。如果页表本身存储在磁盘中,访问页表时可能触发缺页中断。 -
页目录和页表分级加载
如果多级页表结构中的多个级别对应的页面都不在主存,每一级别都会触发一次缺页中断。
内存管理器的间接操作
-
堆栈操作
某些指令(如函数调用或返回)会隐式修改堆栈指针。如果堆栈页面未加载,也会触发缺页中断。 -
动态内存分配
指令可能涉及动态分配的内存区域(如malloc或new),而这些区域的页面可能尚未加载到主存。
¶缺页中断的特殊性
缺页中断在指令执行期间产生和进行处理,而不是在一条指令执行完毕之后。所缺的页面调入之后,重新执行被中断的指令
¶地址变换机构
与分页内存管理方式类似
由逻辑地址检索页表,根据对应页表项的标志位判断,若在内存中,则直接形成物理地址。
如不在内存中,产生缺页中断,从对应页表项的外存地址,从外存找到该页,内存满,则选择页面换出,否则从外存直接调入内存。完成地址转换。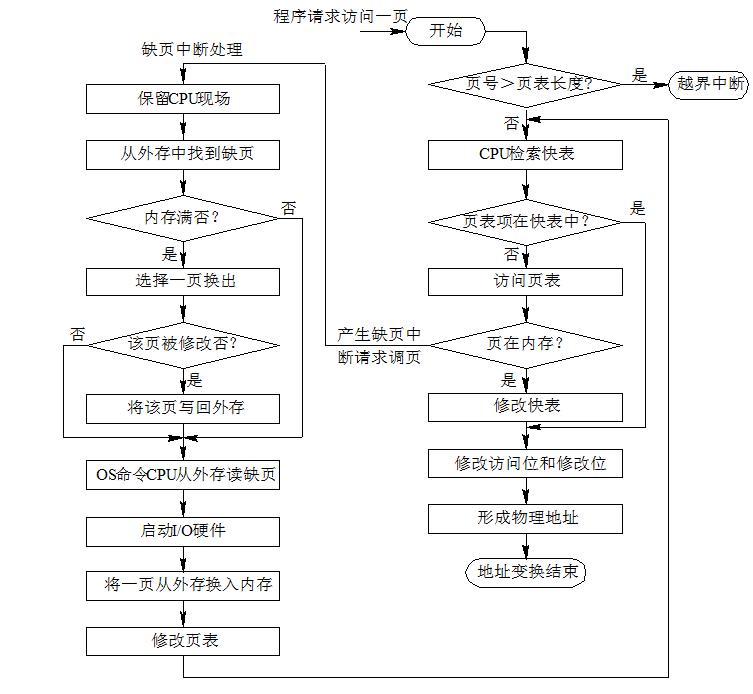
¶内存分配
¶最小物理块数的确定
-
保证进程正常运行所需的最小物理块数
¶物理块的分配策略
-
固定分配,局部置换
-
可变分配,全局置换
-
可变分配,局部置换
固定与可变
固定与可变的区别在于给进程分配的物理块数
即固定是指在给每个进程均分配固定数量的物理块
可变即根据进程的不同,分配不同数量的物理块
全局与局部
即,当进程执行是发生缺页后,换入换出操作执行的范围
局部 即,当进程要执行换入换出操作时,仅在操作系统为该进程分配的物理空间之内发生替换,而不会影响其他进程块
全局 即,当前进程需要换入缺页的部分时,不仅仅会挑选当前进程拥有的物理块,还可能会换出其他进程的物理块。
¶物理块分配算法
-
平均分配算法
-
按比例分配算法
-
考虑优先权的分配算法
对比总结
| 算法类型 | 分配依据 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 平均分配算法 | 平均分配 | 进程需求量相近的场景 | 简单、公平 | 无法动态适应需求,可能浪费资源 |
| 按比例分配算法 | 内存需求比例 | 进程需求量差异大的场景 | 资源利用率高,满足需求较大的进程 | 计算复杂度较高 |
| 考虑优先权的分配算法 | 需求量和优先级 | 多任务场景,优先保证关键任务 | 确保关键任务优先,灵活调整分配策略 | 可能导致低优先级任务资源匮乏 |
在实际系统中,按比例分配算法和考虑优先权的分配算法更常见,因为它们能够更好地适应动态环境的需求。
¶调页策略又称 调页技术详解
¶何时调入页面
-
预调页策略:预先调入一些页面到内存
-
请求调页策略:发现需要访问的页面不在内存时,调入内存
¶从何处调入页面
-
如系统拥有足够的对换区空间,全部从对换区调入所需页面
-
如系统缺少足够的对换区空间,凡是不会被修改的文件,都直接从文件区调入
当换出这些页面时,由于未被修改而不必再将它们重写磁盘,以后再调入时,仍从文件区直接调入
-
UNIX方式:未运行过的页面,从文件区调入;曾经运行过但又被换出的页面,从对换区调入
¶如何调入页面
-
查找所需页在磁盘上的位置
-
查找一内存空闲块:
- 如果有空闲块,就直接使用它
- 如果没有空闲块,使用页面置换算法选择一个"牺牲"内存块
- 将“牺牲”块的内容写到磁盘上,更新页表和物理块表
-
将所需页读入新空闲块,更新页表
-
重启用户进程
¶缺页率
缺页率的计算:
$$
f= F/A
$$
-
影响因素:页面大小、分配内存块的数目、页面置换算法、程序固有属性
缺页中断处理的时间:
$$
t = β×t_a + (1- β)×t_b
$$
例子
存取内存的时间= 200 nanoseconds (ns)
平均缺页处理时间 = 8 milliseconds (ms)
t = (1 – p) × 200ns + p × 8ms
= (1 – p) × 200ns + p ×8,000,000ns
= 200ns + p × 7,999,800ns
如果每1,000次访问中有一个缺页中断,那么:
t = 8.2 ms
这是导致计算机速度放慢 40 倍的影响因子!
¶页面置换算法
功能:需要调入页面时,选择内存中年哪个物理页面被置换。称为replacement policy[4]
目标:把未来不再使用的或短期内较少使用的页面调出,通常只能在局部性原理指导下依据过去的统计数据进行预测;
算法一览
-
最佳算法(OPT, optimal)
-
先进先出算法(FIFO)
-
最近最久未使用算法(LRU, Least Recently Used)
-
轮转算法(clock)
-
最不常用算法(LFU, Least Frequently Used)
-
页面缓冲算法(page buffering)
¶最佳置换算法 OPT
被置换的页将是之后最长时间不被使用的页
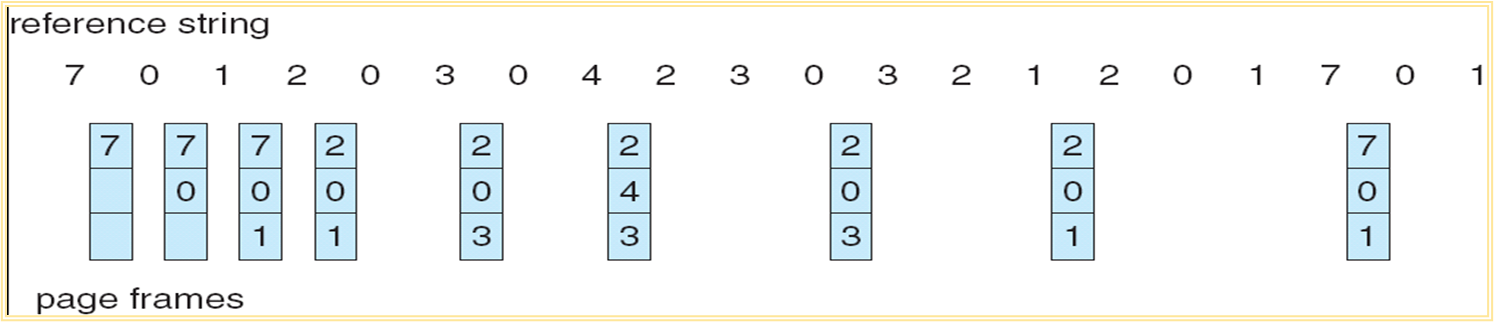
无法实现的算法,可用来评价其他算法
¶先进先出置换算法
总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面予以淘汰
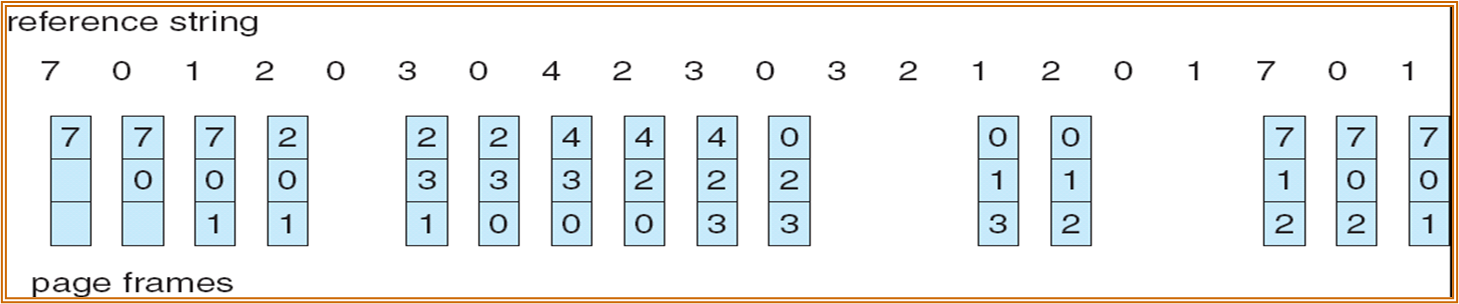
性能较差。较早调入的页往往是经常被访问的页,这些页在FIFO算法下被反复调入和调出。并且有Belady现象。
Belady[5] 现象
采用FIFO算法时,如果对一个进程未分配它所要求的全部页面,有时就会出现分配的页面数增多,缺页率反而提高的异常现象。
Belady现象的描述
一个进程P要访问M个页,OS分配N个内存页面给进程P;对一个访问序列S,发生缺页次数为PE(S,N)。当N增大时,PE(S, N)时而增大,时而减小。
Belady现象的原因
FIFO算法的置换特征与进程访问内存的动态特征是矛盾的,即被置换的页面并不是进程不会访问的。
反而,先加载进去的页面可能是访问次数最多的,如c语言中,定义的函数往往放在
main函数程序入口之前,而且当函数调用另一个函数时,被调用的函数必须放在当前函数之前。
Belady现象的例子
-
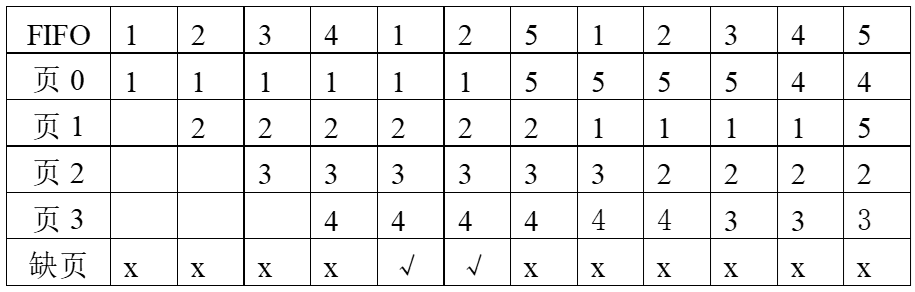
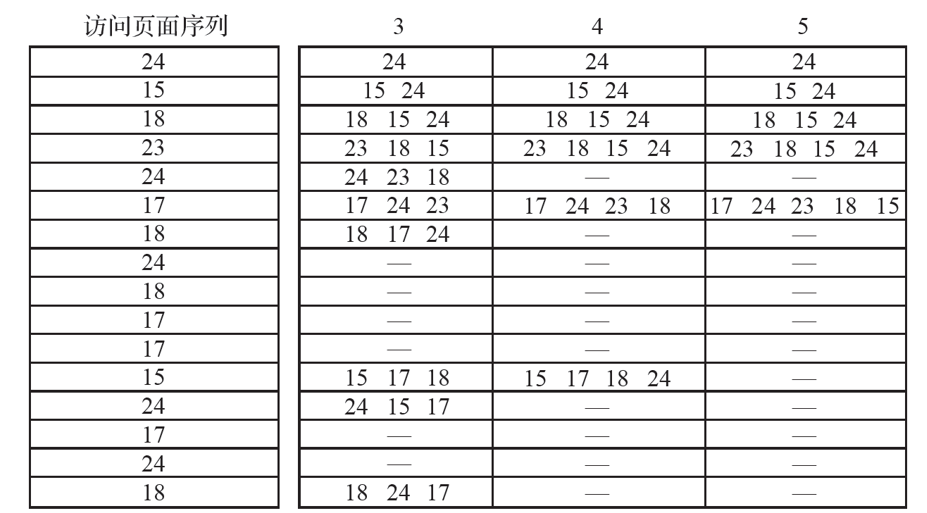
进程P有5页程序访问页的顺序为:1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5;
-
如果在内存中分配3个页面,则缺页情况如下:12次访问中有缺页9次;
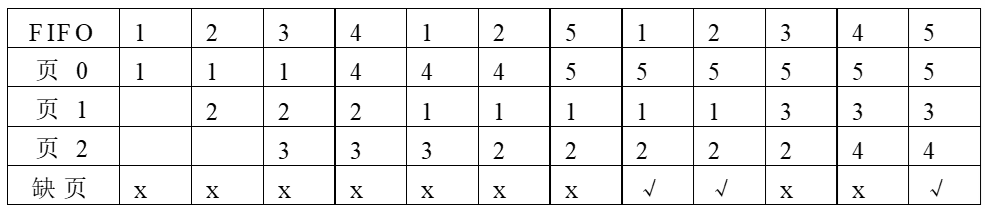
-
如果在内存中分配4个页面,则缺页情况如下:12次访问中有缺页10次
¶最近最久未使用 LRU
选择内存中最久未使用的页面被置换。这是局部性原理的合理近似,性能接近最佳算法。但由于需要记录页面使用时间的先后关系,硬件开销太大。
¶硬件支持
-
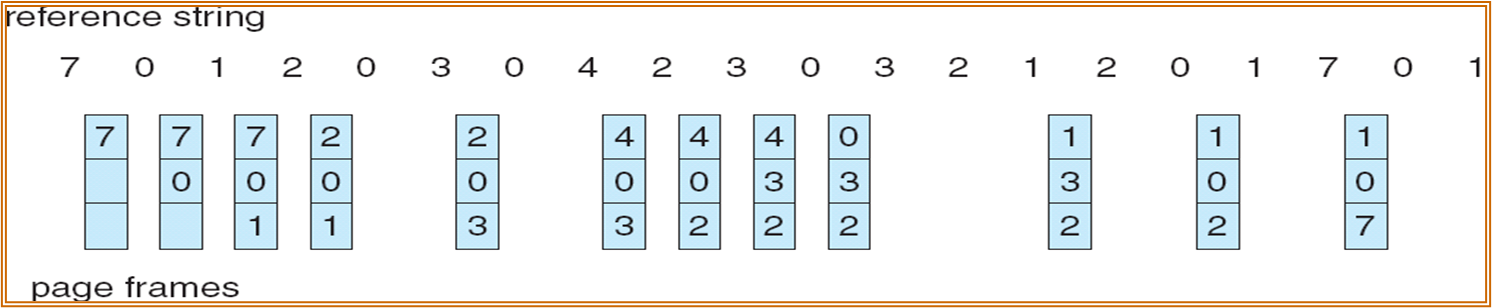
寄存器
为了记录某进程在内存中各页的使用情况,须为每个在内存中的页面配置一个移位寄存器[6],可表示为
$$
R=R_{n-1}R_{n-2}R_{n-3}…R_2R_1R_0
$$某进程具有 8 个页面时的 LRU 访问情况
-
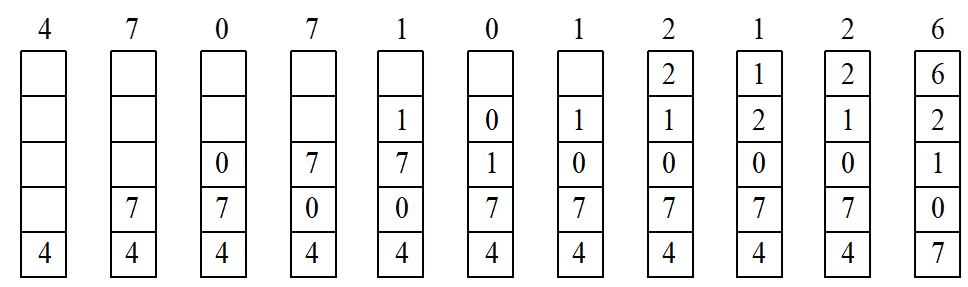
栈
用栈保存时,栈的变换情况
实际实现详细实现过程
最近最久未使用(LRU)算法 的实现可以通过移位寄存器或栈的方式完成。这两种方式各有特点:
1. 用移位寄存器实现 LRU
移位寄存器是一种硬件或软件模拟的寄存结构,通过移位操作记录页面访问的历史。实现过程如下:
-
每个页面框分配一个寄存器,初始值为 0。
-
每次页面访问时,将该寄存器的最高位置为 1,其余位依次右移。
-
未访问的页面寄存器位移后会逐渐变成更小的值。
-
页面置换时,选择寄存器值最小的页面,即最久未使用的页面。
这种实现方式简单直观,但寄存器的位数增加会带来更多硬件需求,因此通常适合于特定规模的小型系统【18】【19】。
2. 用栈实现 LRU
通过栈来管理页面访问,栈顶表示最近使用的页面,栈底表示最久未使用的页面:
-
每次页面被访问时,若其已在栈中,则将其从原位置移除并放到栈顶。
-
若页面不在栈中,则将其直接插入栈顶。
-
如果栈已满,移除栈底元素(最久未使用页面),然后插入新页面。
栈的实现可以通过链表实现动态插入删除操作,同时保证页面顺序的调整。相比移位寄存器,栈方法适合于较大规模的系统,灵活性更高,但需要额外的空间来存储栈【18】【19】。
以上两种方法在实际系统中应用时,还会因性能需求选择优化的数据结构(如哈希表结合链表),以便实现更高效的页面访问与置换管理。
¶Clock置换算法
LRU的近似算法,又称最近未用(NRU)或二次机会页面置换算法
¶简单的Clock算法
-
每个页都与一个访问位相关联,初始值为0
-
当页被访问时置访问位为1
-
置换时选择访问位为0的页 ;若为1,重新置为0
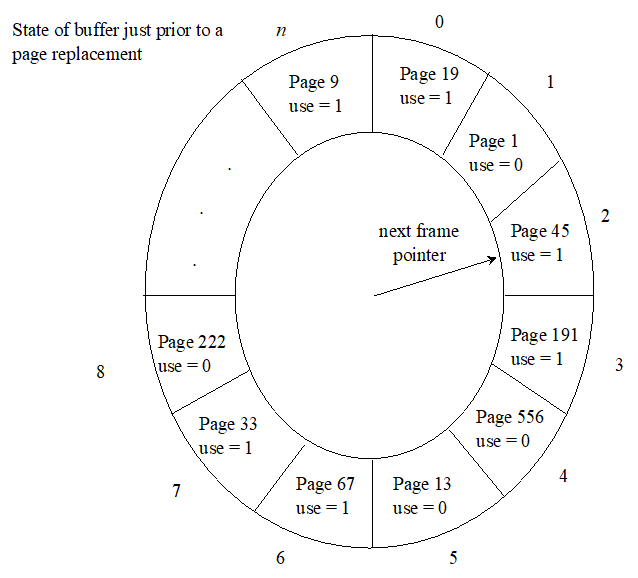
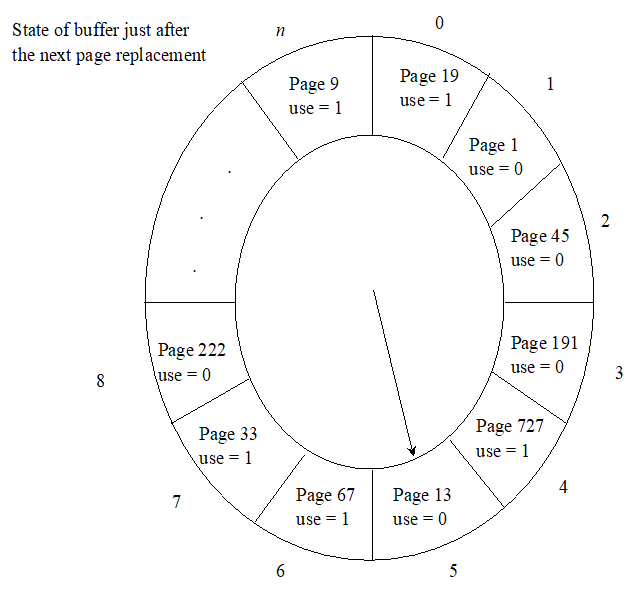
像是时钟一样,在需要进行页表置换时,转着圈访问上图所示的访问位
若顺时针
当转到每一个访问位时,如果当前转到的访问位的值为1,则将该访问位置为0,然后接着访问下一个访问位
直到遇到第一个为0的访问位,则将该访问位对应的页表换出。
概述:当使用clock算法换入缺失的页面后,指针会指向当前换入页的后一个页。
细节辨析
当算法已经选择好了一个页面并将其换出的细节过程
比如替换前的序列
$[\overset{\downarrow}{1_1}, 2_1, 3_1]$
现在需要调入页面$4$在使用clock算法计算后:
$[\overset{\downarrow}{1_0}, 2_0, 3_0]$
此时页面$1$被选择,然后替换
$[\overset{\downarrow}{4_1}, 2_1, 3_1]$
然后指针指向刚换入页面的后一个页面
$[{1_1}, \overset{\downarrow}{2_1}, 3_1]$
然后才完成一次完整的$clock$
¶改进Clock置换算法
除须考虑页面的使用情况外,还须增加置换代价
考虑置换代价,即考虑当前页表是否被修改
因为被修改的页表,需要写入磁盘更加耗时
没有被修改的页表,在换出后直接丢掉就好了
即,淘汰时,同时检查访问位A与修改位M
-
第1类(A=0,M=0):表示该页最近既未被访问、又未被修改,是最佳淘汰页。
-
第2类(A=0,M=1):表示该页最近未被访问,但已被修改,并不是很好的淘汰页。
-
第3类(A=1,M=0):表示该页最近已被访问,但未被修改,该页有可能再被访问。
-
第4类(A=1,M=1):表示该页最近已被访问且被修改,该页有可能再被访问。
置换时,循环依次查找第1类、第2类页面,找到为止。
¶最少使用置换算法 LFU详细解释
为内存中的每个页面设置一个移位寄存器,用来记录该页面的被访问频率
LFU 选择在最近时期使用最少的额页面内作为淘汰页
¶页面缓冲算法 PBA
是对 FIFO[7] 算法的发展,通过被置换页面的缓冲,有机会找回刚被置换的页面
¶被置换页面的选择和处理:
用 FIFO 算法选择被置换页,把被置换的页面放入两个链表之一
-
如果页面未被修改,就将其归入到空闲页面链表的末尾
-
否则将其归入到已修改页面链表。
¶处理过程
需要调入新的物理页面时,将新页面内容读入到空闲页面链表的第一项所指的页面,然后将第一项删除。
空闲页面和已修改页面,仍停留在内存中一段时间,如果这些页面再次被访问,只需要较小的开销就可以将被访问的页面返还,重新作为进程的内容页。
其实,空闲页面链表和已修改页面链表就像两个缓冲区,等过了缓冲时间任未访问的页面就真的扔了。
当已修改页面达到一定次数后,在将它们一起调出到外存,然后将他们归入空闲页面链表,这样能大大减少I/O操作次数也相当于是一个缓冲区吧,页表I/O缓冲区,因为I/O操作比较慢
¶访问内存的有效时间
系统中有快表,
具有快表的请求分页管理方式的内存访问操作:
(1)被访问页在内存中,对应页表项在快表中
EAT=λ+t
(2)被访问页在内存中,对应页表项不在快表中
EAT=λ+t+λ+t=2×(λ+t)
(3)被访问页不在内存中
EAT= λ+t+ε+λ+t=2×(λ+t)+ε
(4)快表命中率为a,缺页率为f,缺页中断处理时间为ε
EAT= λ+a×t+(1-a)×((1-f)×(λ+t)+f×(t+ε+ λ)+t)
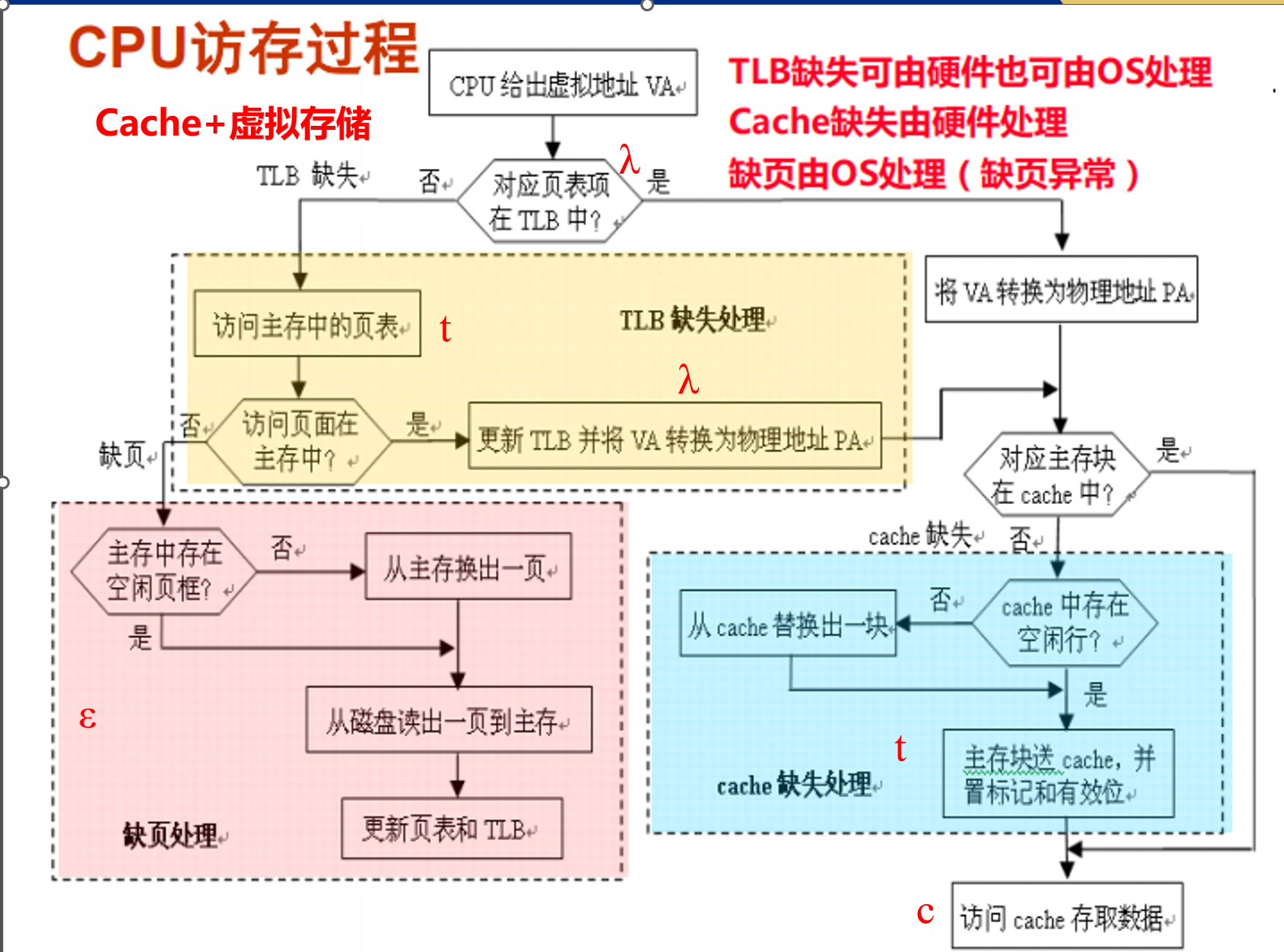
勘误
严格按照上图中的过程计算
声明

完整过程描述:
一个有快表的系统,同时系统中不存在Cache
-
首先是快表命中的情况
- 查询快表,进行地址转换(访问快表)
- 访问对应的页(访问内存)
-
然后是快表未命中的情况
- 查询快表,发现没有命中(访问快表)
- 查询内存中的页表(访问内存)
- 访问对应的页,在该处又会产生两种情况
- 没有发生缺页,访问对应的页(访问内存)
- 发生缺页
- 先执行缺页处理(缺页处理)
- 在访问对应的页(访问内存)
¶抖动与工作集
¶抖动/颠簸(Thrashing)
页面在内存与外存之间频繁调度,以至于调度页面所需时间比进程实际运行的时间还多,此时系统效率急剧下降,甚至导致系统崩溃。这种现象为颠簸。
¶原因
-
系统中运行的进程太多
-
页面淘汰算法不合理
-
分配给进程的物理页面数太少
¶常驻集
常驻集指虚拟页式管理中给进程分配的物理页面。
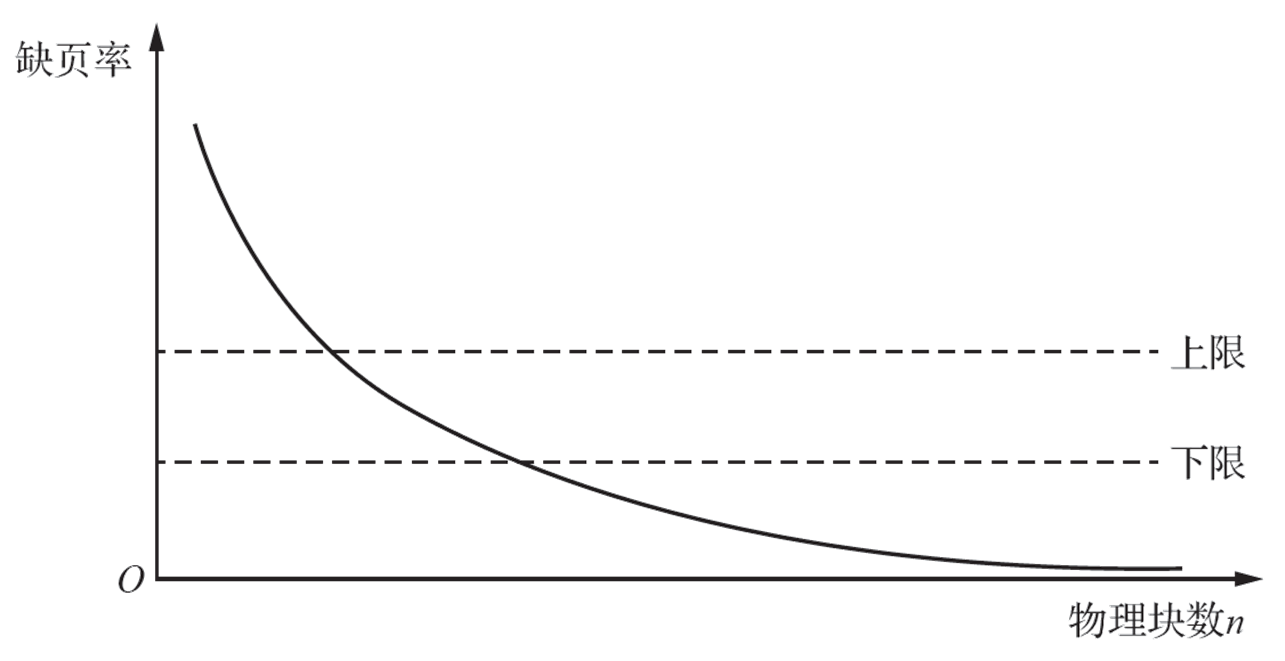
¶工作集
1968年由Denning提出,目的是依据进程在过去的一段时间内访问的页面来调整常驻集大小。
所谓工作集,指在某段时间间隔Δ里进程实际要访问页面的集合。
把某进程在时间t的工作集记为w(t,Δ),其中的变量Δ称为工作集的“窗口尺寸”
-
$\Delta$是一个虚拟时间段,称为窗口大小(window size),它采用"虚拟时间"单位(阻塞时不计时),大致可以用执行的指令数目,或处理器执行时间来计算;
-
工作集是在[t - $\Delta$, t]时间段内所访问的页面的集合;
-
| W(t, $\Delta$) | 指工作集大小即页面数目;
¶抖动的预防方法
-
采取局部置换策略:只能在分配给自己的内存空间内进行置换;
-
把工作集算法融入到处理机调度中,让常驻集包含工作集;
-
利用“L=S”准则调节缺页率:
L是缺页之间的平均时间 S是平均缺页服务时间,即用于置换一个页面的时间 -
L>S,说明很少发生缺页
-
L<S,说明频繁缺页
-
L=S,磁盘和处理机都可达到最大利用率
-
-
选择暂停进程。
相关注解
- 调入功能 是 指将进程所需的数据或指令从磁盘调入主存 ↩
- 进程页表 是操作系统管理虚拟存储器时,用于映射进程的 虚拟地址和 物理地址 的一个重要数据结构。
每个进程都有自己的 页表 ,它记录了该进程所有虚拟页的相关信息,
包括虚拟页是否已被加载到主存以及其对应的物理页框地址。 ↩ - CISC(Complex Instruction Set Computer) 架构是一种处理器设计理念,其特点是提供 复杂且多样化的指令集 ↩
- policy:/ˈpɒləsi/ n. 策略;方针; ↩
- 贝拉迪 贝拉迪异常(Belady's anomaly)是一种计算机科学中的现象,指的是在某些页面置换算法中,增加可用的物理内存可能导致更多的页面错误 ↩
- 移位寄存器(Shift Register)是一种数字电路,用于将数据按照一定规则在其存储单元之间移动。它是由一组触发器(Flip-Flop)组成的逻辑电路,每个触发器存储一个位数据。 ↩
- 先进先出算法 ↩